 Michael Wan Interactive Insights
Michael Wan Interactive Insights This article explains the ICLR 2024 paper Vision Transformers Need Registers by Darcet et al., which discovered a surprising phenomenon in large ViT models and proposed an elegantly simple fix.
One idea holds this whole story together: the artifacts are the model asking for scratch space. A large ViT needs somewhere to stash global information mid-computation, has no dedicated slot for it, and so hijacks the least useful patch tokens. The fix is to simply hand it the scratch space it was improvising. Everything below is that arc — the symptom, the diagnosis, the one-line cure.
The Mystery: Artifacts in Vision Transformers
Something strange happens in large Vision Transformers. When you visualize their attention maps or feature norms, you see scattered “spikes”—patches with abnormally high values appearing in seemingly random locations, mostly in uniform background regions.
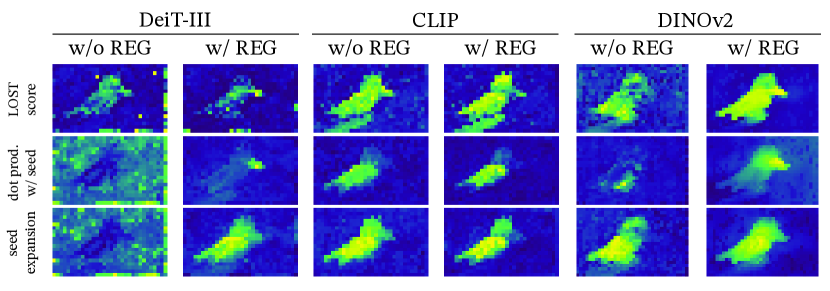
These aren’t random glitches. They appear consistently across different training paradigms:
- DeiT-III (supervised on labels)
- OpenCLIP (supervised on text-image pairs)
- DINOv2 (self-supervised)
The only model that doesn’t show these artifacts? The original DINO. Understanding why reveals something fundamental about how Vision Transformers process information.
Characterizing the Artifacts
They Have Extremely High Norms
The artifacts correspond to tokens whose output feature vectors have roughly 10x higher norm than normal patches. When you plot the distribution of token norms across many images, you see a clear bimodal pattern:

They Appear in Low-Information Regions
Where do these high-norm tokens appear? Not randomly—they concentrate in patches that look similar to their neighbors. Areas of uniform color, texture, or background.
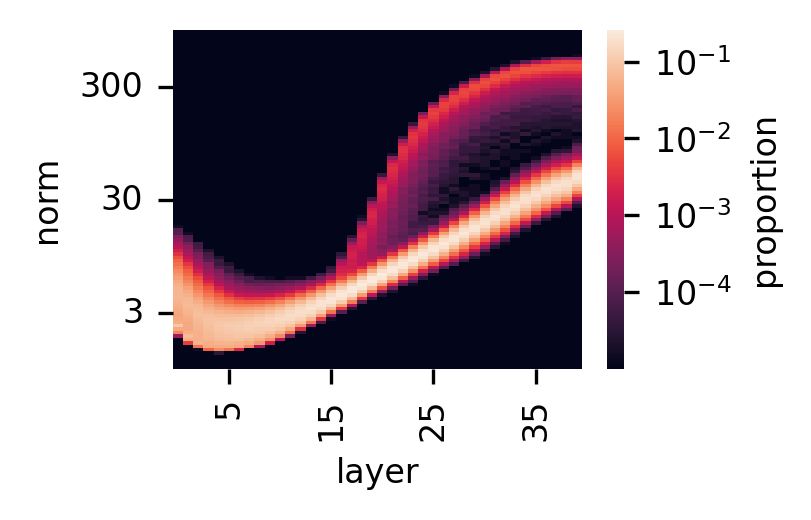
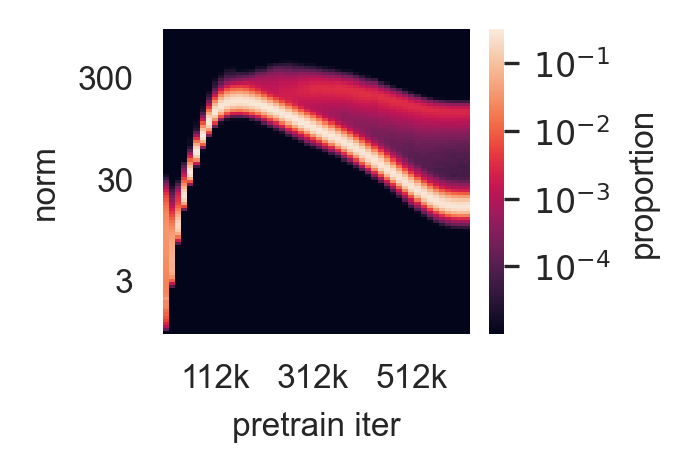
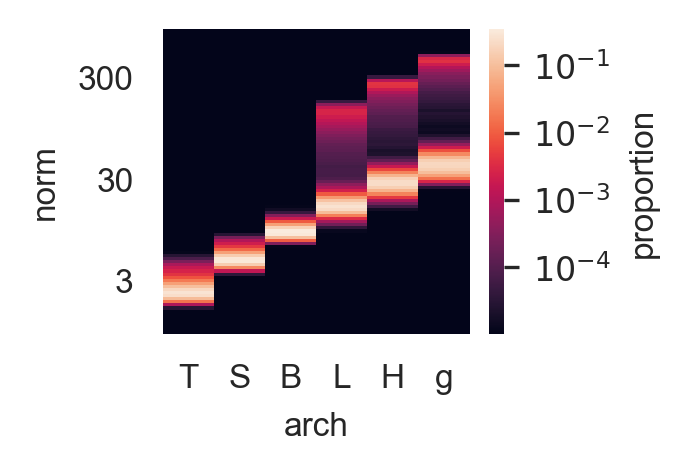
They Emerge Mid-Network, Mid-Training, in Large Models
The artifacts don’t exist from the start. They develop under specific conditions:
| Condition | Artifacts Present? |
|---|---|
| Early layers (1-10) | None |
| Middle layers (15+) | Present |
| Early training (<33%) | None |
| Late training (>33%) | Present |
| Small models (ViT-S/B) | None |
| Large models (ViT-L/H/g) | Present |
This pattern suggests the artifacts are an emergent behavior—something the model learns to do when it has enough capacity and training time.
The Hypothesis: Recycled Tokens for Global Computation
Why would a model create these strange high-norm tokens? The paper proposes a compelling explanation:
Evidence: What Do Outlier Tokens Encode?
The authors probe what information these tokens contain:
Local information (patch position, pixel reconstruction):
- Normal tokens: 41.7% position accuracy, 18.38 reconstruction error
- Outlier tokens: 22.8% position accuracy, 25.23 reconstruction error
Global information (image classification):
- Normal tokens: 65.8% ImageNet accuracy
- Outlier tokens: 69.0% ImageNet accuracy
- [CLS] token: 86.0% ImageNet accuracy
Read the numbers as a swap. The outlier tokens got worse at their original job — reporting where they are and what pixels they cover (position accuracy drops 41.7% → 22.8%). They got better at a job that was never theirs: summarizing the whole image (classification 65.8% → 69.0%). The model overwrote a local patch with a global summary. They are functioning as informal registers, built by hijacking patches that “shouldn’t matter.”
The Problem: Why This Matters
If the model works, why care about these artifacts?
1. Corrupted Feature Maps
Dense prediction tasks (segmentation, depth estimation, object detection) rely on spatially coherent feature maps. Artifacts introduce noise:



2. Broken Object Discovery
Methods like LOST (Large-scale Object diScovery from self-supervised Transformers) use attention maps to find objects. Artifacts catastrophically break these methods for large models—which is why researchers were stuck using smaller, less capable models.
3. Uninterpretable Attention
Attention visualization is a key tool for understanding what models “see.” Artifacts make attention maps nearly useless for interpretation.
The Solution: Explicit Register Tokens
The fix is remarkably simple: give the model dedicated tokens for internal computation.
In words: prepend a handful of extra tokens that are not patches and not the class token. They have no pixels behind them and no output job. They exist only to give attention heads a legitimate place to read and write global information — the scratch pad the model was previously carving out of the background.
How Registers Work
- Add N learnable tokens to the input sequence (after [CLS], before patches)
- Train normally—registers participate in all attention operations
- Discard registers at output—only use [CLS] and patch tokens for downstream tasks
How Many Registers?
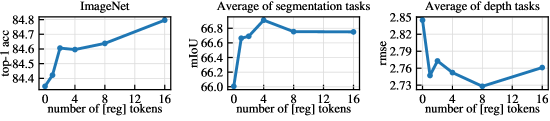
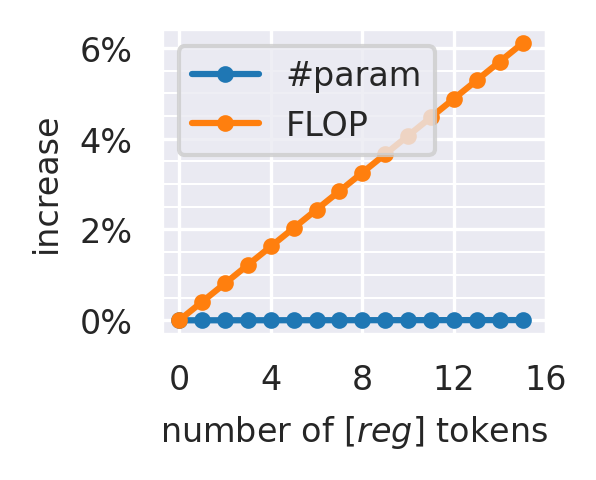
| Registers | Artifacts | Performance | Overhead |
|---|---|---|---|
| 0 | Present | Baseline | 0% |
| 1 | Eliminated | Slight drop | ~0.5% |
| 4 | Eliminated | Optimal | <2% |
| 16 | Eliminated | Saturated | ~6% |
The sweet spot is 4 registers: artifacts completely gone, optimal downstream performance, and less than 2% computational overhead.
The one real cost is not compute — it is that registers must be present from the start of training. You cannot bolt them onto a pretrained checkpoint and expect the artifacts to migrate; the model learned its hijacking behavior during pretraining. Fixing an existing model means retraining it, which for a DINOv2-scale run is the actual price of this “free” fix.
Results: Registers Fix Everything
Artifact Elimination
Dense Prediction Tasks
Performance on semantic segmentation (ADE20k) and depth estimation (NYUd):
| Model | ImageNet | ADE20k (mIoU) | NYUd (RMSE↓) |
|---|---|---|---|
| DeiT-III | 84.7 → 84.7 | 38.9 → 39.1 | 0.511 → 0.512 |
| OpenCLIP | 78.2 → 78.1 | 26.6 → 26.7 | 0.702 → 0.661 |
| DINOv2 | 84.3 → 84.8 | 46.6 → 47.9 | 0.378 → 0.366 |
Registers maintain or improve performance across the board. DINOv2 sees the largest gains.
Object Discovery Unlocked
The most dramatic improvement comes from object discovery methods like LOST:
| Model | VOC 2007 | VOC 2012 | COCO 20k |
|---|---|---|---|
| DeiT-III | 11.7 → 27.1 | 13.1 → 32.7 | 10.7 → 25.1 |
| DINOv2 | 35.3 → 55.4 | 40.2 → 60.0 | 26.9 → 42.0 |
What Do Registers Learn?
Without any explicit supervision, registers spontaneously specialize:

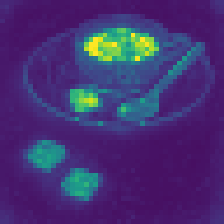
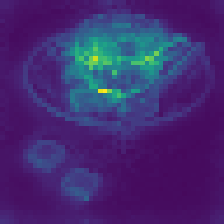
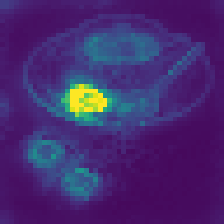
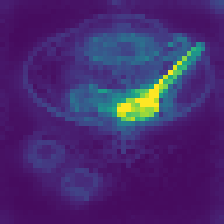
Each register develops its own “role” in processing the image—some attend to central objects, others to boundaries, others to textures. The model figures out how to use this extra computational workspace on its own.
Interactive: Norm Distribution Explorer
Explore how token norms distribute across a ViT’s output. Adjust the threshold to see how many tokens would be classified as “outliers.”
Why This Matters Beyond ViTs
This paper reveals something fundamental about how Transformers process information:
-
Emergence of internal structure: Given enough capacity and training, models develop their own computational primitives—even without being told to.
-
The cost of implicit computation: When models repurpose input tokens for computation, it corrupts the representational space. Explicit workspace is better.
-
Simple fixes for complex problems: The solution isn’t architectural surgery—it’s just adding 4 tokens. Sometimes the best interventions are minimal.
Takeaways
-
Large Vision Transformers develop artifacts—high-norm tokens in low-information regions that serve as informal registers for global computation.
-
Adding explicit register tokens eliminates these artifacts with negligible overhead (<2% FLOPs, ~0.1% parameters).
-
Registers improve dense prediction tasks and unlock object discovery methods for large models.
-
4 registers is the sweet spot—enough to eliminate artifacts and optimize performance.
-
Registers spontaneously specialize into different functional roles without supervision.
The paper demonstrates that understanding why neural networks develop certain behaviors—even strange ones—can lead to simple, principled improvements.
References
-
Darcet, T., Oquab, M., Mairal, J., & Bojanowski, P. (2024). Vision Transformers Need Registers. ICLR 2024.
-
Oquab, M., et al. (2023). DINOv2: Learning Robust Visual Features without Supervision.
-
Touvron, H., et al. (2022). DeiT III: Revenge of the ViT.
-
Radford, A., et al. (2021). Learning Transferable Visual Models From Natural Language Supervision (CLIP).
-
Siméoni, O., et al. (2021). Localizing Objects with Self-Supervised Transformers and no Labels (LOST).
-
Xiao, G., Tian, Y., Chen, B., Han, S., & Lewis, M. (2023). Efficient Streaming Language Models with Attention Sinks.