 Michael Wan Interactive Insights
Michael Wan Interactive Insights This article explains the paper FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness by Dao et al. (2022), which introduced an algorithm that makes transformer attention 2-4x faster without any approximation.
One idea runs through this whole article: on a modern GPU, the memory hierarchy is the algorithm. FlashAttention computes the exact same softmax attention as the textbook version. It is faster only because it moves less data. Keep that framing in mind and every design choice below follows from it.
The Problem: Attention is Memory-Bound
Standard self-attention scales quadratically with sequence length. For a sequence of length $N$, we compute and store an $N \times N$ attention matrix.
Read this as: score every query against every key ($QK^T$), squash the scores into a probability distribution per row (softmax), then take a weighted average of the value vectors. The $N \times N$ score matrix in the middle is the expensive object — it grows with the square of the sequence.
Here is the twist. The bottleneck is not the arithmetic — it is the memory access. An NVIDIA A100 can do 312 TFLOPS of matrix math, but its main memory delivers data far slower than the tensor cores can consume it. So the chip spends most of its time waiting for numbers to arrive, not multiplying them.
GPU Memory Hierarchy
To understand FlashAttention, we need to understand how GPU memory works.
(Q, K, V, O)
GPUs have two main memory types:
HBM (High Bandwidth Memory)
- Size: 40-80 GB on A100
- Bandwidth: 1.5-2.0 TB/s
- Role: Main GPU memory where model weights and activations live
SRAM (On-chip Cache)
- Size: ~20 MB total (192 KB per streaming multiprocessor × 108 SMs)
- Bandwidth: ~19 TB/s
- Role: Fast scratch space for active computation
The key numbers: SRAM is ~10x faster but ~1000x smaller than HBM.
To make the gap concrete: a 4K-token attention matrix in fp16 is $4096 \times 4096 \times 2 \approx 34$ MB per head. Writing it to HBM and reading it back is ~68 MB of traffic at 1.5 TB/s ≈ 45 microseconds of pure data movement — before a single useful multiply. Multiply that by many heads and layers and the copies, not the math, set the runtime.
Standard Attention: The Memory Problem
Let’s trace what standard attention does:
The red steps are the waste: we write the $N \times N$ matrix to HBM and read it straight back, twice. The score matrix never needed to leave the chip — the standard implementation evicts it only because it computes softmax in separate passes. For long sequences, these round-trips dominate runtime.
The $N^2$ term is the killer. Loading $Q, K, V$ costs $\Theta(Nd)$, but materializing and re-reading the score matrix costs $\Theta(N^2)$ — and for long sequences $N^2 \gg Nd$. Every byte of that term is optional.
FlashAttention: The Solution
FlashAttention’s key idea: never materialize the full attention matrix. Instead, compute attention in tiles that fit in SRAM.
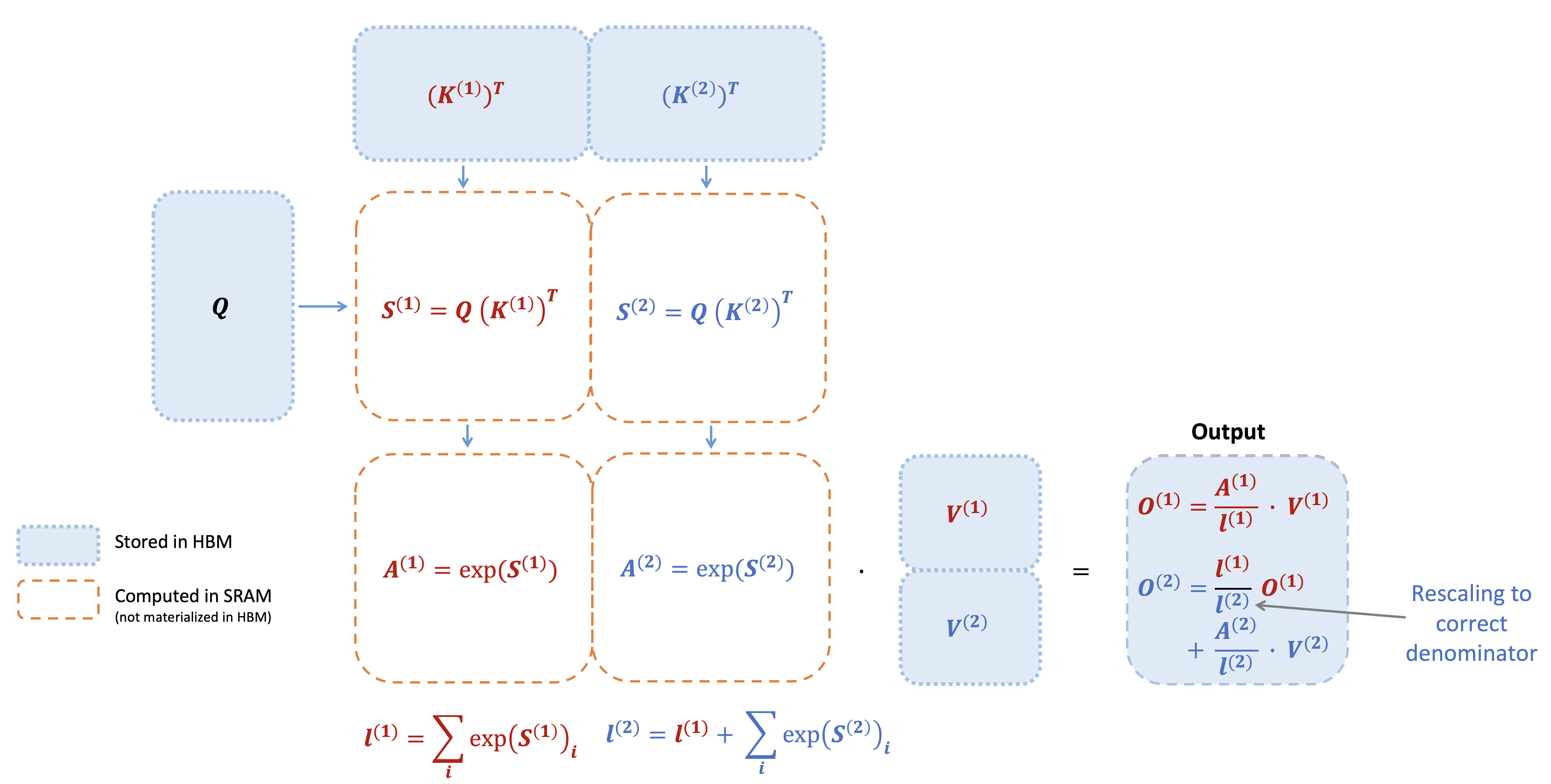
The Tiling Strategy
Instead of computing the full attention matrix at once:
- Divide Q, K, V into blocks that fit in SRAM
- Compute attention for each block pair
- Accumulate results with proper normalization
But there’s a catch: softmax isn’t block-decomposable. The denominator is a sum over the whole row, so you seem to need every key before you can normalize any of them. How do you normalize a row you’ve only seen part of?
The Online Softmax Trick
This is the algorithmic insight that makes tiling possible.
Standard softmax needs two passes over each row:
- Find the maximum (subtracted for numerical stability, so $e^{x}$ never overflows).
- Compute every $e^{x_i - \max}$ and sum them into the denominator.
Online softmax fuses both into a single pass by carrying two running numbers per row — the max seen so far ($m$) and the running denominator ($\ell$) — and correcting them each time a new block arrives.
Line by line: the first equation just updates the running max. The second re-expresses the old denominator in terms of the new max (the $e^{m^{old}-m^{new}}$ factor shrinks the old sum to match the new, larger baseline) and adds the new block’s contribution. The third does the same correction to the running output before folding in the new block’s $\tilde{P}V$.
The trick is the correction factor $e^{m^{old}-m^{new}}$. When a later block reveals a larger maximum, we retroactively rescale everything computed so far — as if we had known the true max all along. Because the fix-up is exact, the block-by-block result equals the single-shot softmax to the last bit.
The Algorithm
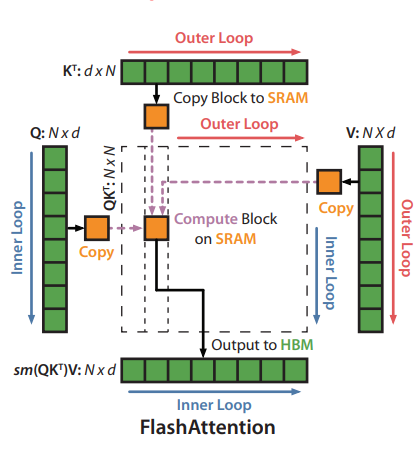
Here’s the FlashAttention forward pass:
Input: Matrices $Q, K, V \in \mathbb{R}^{N \times d}$ in HBM, block sizes $B_r, B_c$
Output: $O \in \mathbb{R}^{N \times d}$
-
Divide $Q$ into $T_r = \lceil N/B_r \rceil$ blocks, $K, V$ into $T_c = \lceil N/B_c \rceil$ blocks
-
Initialize $O = 0$, $\ell = 0$, $m = -\infty$ in HBM
-
For $j = 1, \ldots, T_c$ (outer loop over K, V):
- Load $K_j, V_j$ from HBM to SRAM
-
For $i = 1, \ldots, T_r$ (inner loop over Q):
- Load $Q_i, O_i, \ell_i, m_i$ from HBM to SRAM
- On chip, compute $S_{ij} = Q_i K_j^T \in \mathbb{R}^{B_r \times B_c}$
- On chip, compute:
- $\tilde{m}_{ij} = \text{rowmax}(S_{ij}) \in \mathbb{R}^{B_r}$
- $\tilde{P}_{ij} = \exp(S_{ij} - \tilde{m}_{ij}) \in \mathbb{R}^{B_r \times B_c}$
- $\tilde{\ell}_{ij} = \text{rowsum}(\tilde{P}_{ij}) \in \mathbb{R}^{B_r}$
- Update $m_i^{\text{new}}, \ell_i^{\text{new}}, O_i$ using online softmax
- Write $O_i, \ell_i, m_i$ to HBM
-
Return $O$
The critical property: the $N \times N$ attention matrix $S$ is never fully materialized in HBM. Each block $S_{ij}$ exists only briefly in SRAM.
Where $M$ is SRAM size. The $N^2$ term from standard attention is gone — replaced by a term that shrinks as SRAM grows. Bigger fast cache means bigger tiles, means fewer trips to HBM. For typical values ($d = 64$, $M = 100$KB), this is 5-20x fewer HBM accesses, and the exact same output.
Why It Works: Arithmetic Intensity
Arithmetic intensity = FLOPs / bytes moved
Standard attention has low arithmetic intensity: we move lots of data for relatively little compute. FlashAttention increases arithmetic intensity by reusing data in SRAM.
| Method | HBM Reads/Writes | Arithmetic Intensity |
|---|---|---|
| Standard Attention | $\Theta(Nd + N^2)$ | Low — cores starve |
| FlashAttention | $O(N^2d^2/M)$ | High — cores stay fed |
Results
FlashAttention achieves significant speedups across different models and sequence lengths:
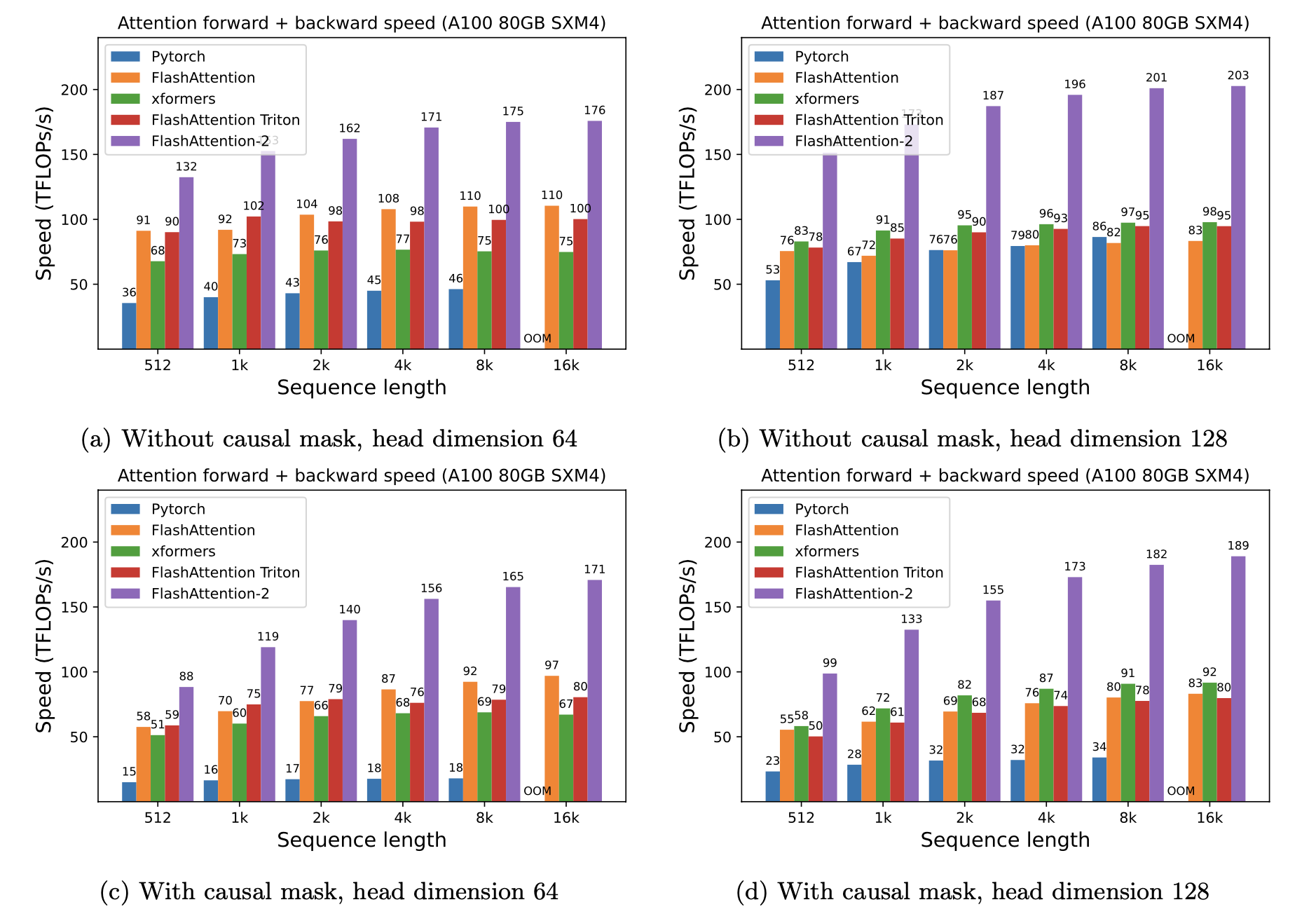
| Model | Sequence Length | Speedup |
|---|---|---|
| BERT-large | 512 | 15% faster end-to-end |
| GPT-2 | 1K | 3× faster |
| Long-range arena | 1K-4K | 2.4× faster |
More importantly, FlashAttention enables much longer sequences. Because memory now grows linearly with $N$ instead of quadratically, sequences that once ran out of memory become feasible. The paper shows the first Transformer to reach better-than-random accuracy on Path-X (16K tokens) and Path-256 (64K tokens). This is the through-line paying off: respecting the memory hierarchy did not just speed up attention — it changed what lengths are trainable at all.
What does FlashAttention give up? It trades extra FLOPs for fewer memory accesses. The backward pass recomputes attention blocks on the fly rather than reading a stored matrix, so total arithmetic goes up — and it still wins, because on a memory-bound workload FLOPs are nearly free. The real costs are engineering ones: a hand-tuned fused kernel per hardware generation, and none of the composability of stock framework ops.
Extensions: FlashAttention-2 and 3
The original algorithm fixed the memory problem. The follow-ups chase the remaining hardware inefficiencies — the same through-line, one hardware generation at a time.
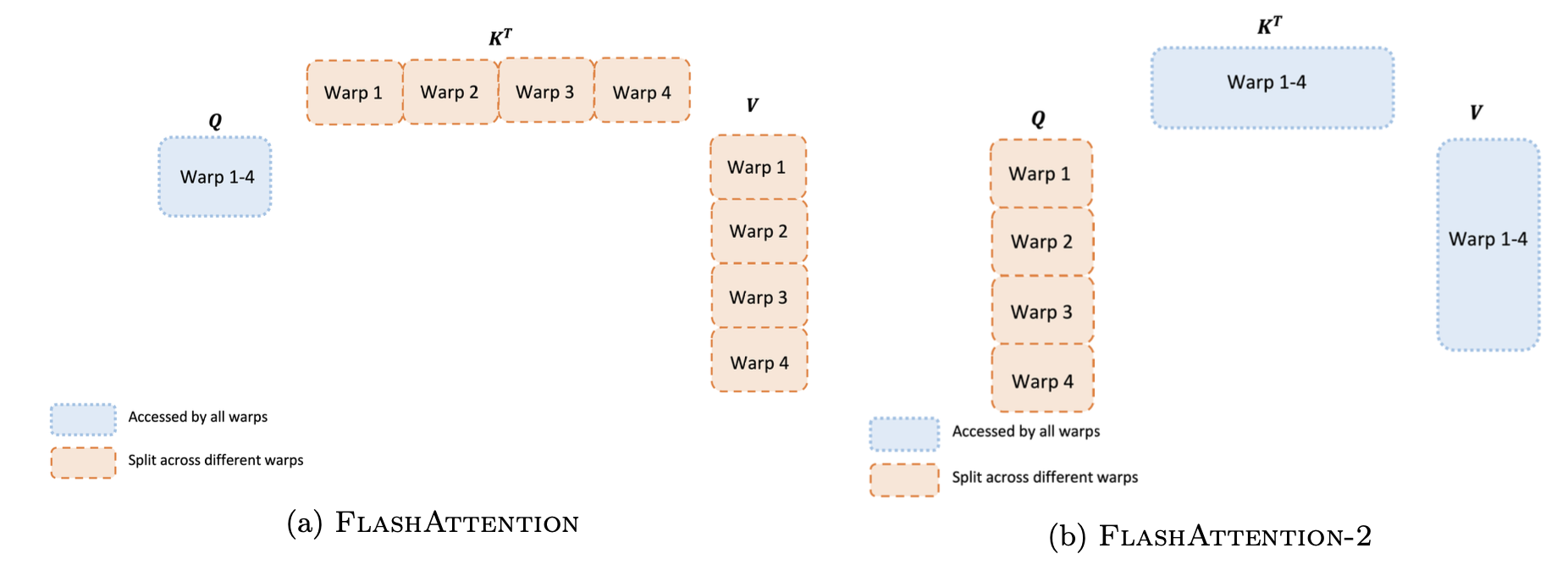
FlashAttention-2 (2023) improves parallelism:
- Better work partitioning across GPU thread blocks, so more of the GPU stays busy
- Fewer non-matmul FLOPs (rescaling and exp are slow relative to tensor-core matmuls)
- Roughly 2× faster than FlashAttention-1, reaching ~50-70% of the A100’s theoretical peak
FlashAttention-3 (2024) leverages new hardware features:
- Asynchronous execution — overlap the matmul on the tensor cores with the softmax rescaling, so neither waits for the other
- FP8 low-precision support for even higher throughput
- Reaches ~75% of the H100’s peak FLOPs; up to ~1.2 PFLOPS in FP8
scaled_dot_product_attention), vLLM, and essentially every production serving stack.
Key Takeaways
References
-
Dao, T., Fu, D. Y., Ermon, S., Rudra, A., & Ré, C. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. NeurIPS 2022.
-
Dao, T. (2023). FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning.
-
Shah, J., Bikshandi, G., Zhang, Y., Thakkar, V., Ramani, P., & Dao, T. (2024). FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision.
-
Milakov, M., & Gimelshein, N. (2018). Online Normalizer Calculation for Softmax. arXiv:1805.02867.