 Michael Wan Interactive Insights
Michael Wan Interactive Insights This article explains the landmark paper BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding by Devlin et al. (2018), which introduced a new paradigm for NLP: pre-train once, fine-tune everywhere.
Introduction
By 2018, computer vision had a recipe everyone used: train a big model on ImageNet, then fine-tune it for your task. Language had no equivalent. Every new NLP problem still meant designing a new architecture and training it from scratch.
Two approaches were circling the answer:
- Feature-based (ELMo): pre-train embeddings, freeze them, bolt a task-specific model on top
- Fine-tuning (GPT): pre-train one language model, fine-tune the whole thing—but reading only left to right
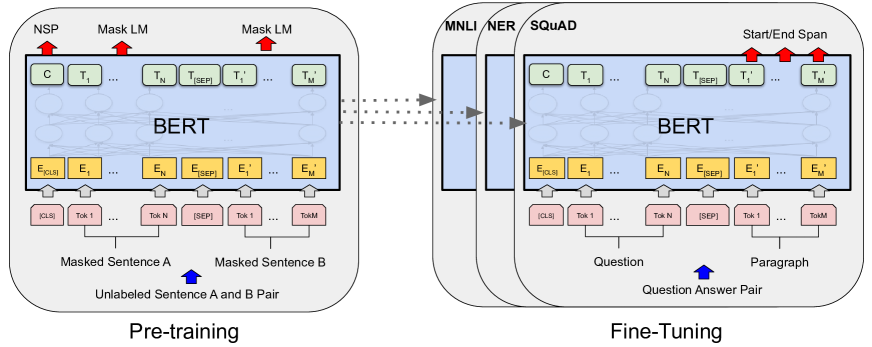
BERT took the best of both and removed their shared weakness. One pre-trained model, fine-tuned end to end for almost any task, reading context from both directions at once. The rest of this article is about why “both directions” was the hard part—and the trick that made it work.
The Directionality Problem
Why direction matters
Consider the sentence:
To understand “bank” correctly, you need:
- Left context: “The” (not very helpful)
- Right context: “by the river” (critical—this means riverbank, not financial institution)
A left-to-right language model can’t use the right context when processing “bank.” It’s fundamentally limited.
Previous solutions
ELMo trained two separate LSTMs—one left-to-right, one right-to-left—and concatenated their outputs. This captures both directions, but the two directions don’t interact during training. Each direction is learned independently.
GPT used a Transformer decoder, but it’s autoregressive: each position can only attend to positions on its left. It’s powerful, but still unidirectional.
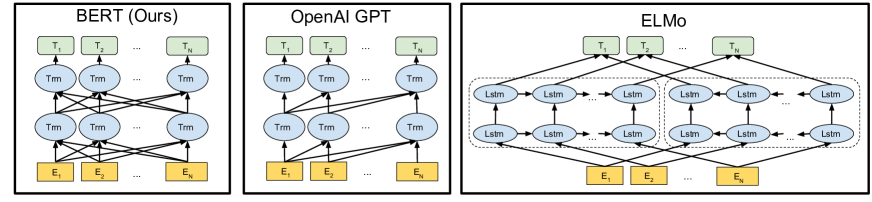
The Bidirectional Challenge
The problem with “just make it bidirectional” is subtle but fundamental.
In a standard language model, you predict the next word given previous words:
Read it as: the probability of word $w_t$ given everything before it. The target word is never part of its own context, so the task stays honest.
But turn on bidirectional attention and that guarantee is gone. If word $w_t$ can attend to $w_{t+1}$, and $w_{t+1}$ can attend back to $w_t$, then predicting $w_t$ lets it peek at itself through its neighbors. The model would learn to copy instead of understand.
BERT’s insight: don’t predict the next word. Hide some words, then predict the ones you hid.
Masked Language Modeling (MLM)
The core pre-training objective of BERT is the Masked Language Model.
The procedure
- Take a sentence (or sentence pair)
- Randomly select 15% of tokens to “mask”
- Of those selected tokens:
- 80% → replace with
[MASK]token - 10% → replace with a random word
- 10% → keep unchanged
- 80% → replace with
- Train the model to predict the original tokens
Why the 80/10/10 split?
If we always used [MASK], the model would never see real words in those positions during pre-training—but during fine-tuning there are no [MASK] tokens at all. The model would be tuned for an input distribution it never meets in production.
The 10% random replacement teaches the model that it can’t just trust every token it sees. The 10% unchanged teaches it to keep reasoning from context even when a token looks perfectly normal.
The equation
For each masked position $i$, BERT outputs a distribution over the vocabulary:
In words: take the hidden state $h_i$ that BERT computed for the masked slot—a vector that has already absorbed the whole sentence through self-attention—project it onto the 30,000-word vocabulary, and softmax to get a probability for each candidate word. Training nudges those probabilities toward the word that was actually hidden.
Try it: mask a word and watch BERT guess
Click any word below to hide it. The bars show what a bidirectional model predicts for the blank, using context from both sides of the gap.
Next Sentence Prediction (NSP)
Many NLP tasks require understanding relationships between sentences, not just within them: question answering, natural language inference, etc.
BERT adds a second pre-training objective: Next Sentence Prediction.
The procedure
- Sample sentence pairs (A, B) from the corpus
- 50% of the time: B is the actual next sentence after A (label:
IsNext) - 50% of the time: B is a random sentence (label:
NotNext) - Train the model to classify the pair
Input format
BERT packs both sentences into a single sequence:
The [CLS] token’s output becomes the aggregate sequence representation, used for sentence-level predictions.
BERT Architecture
BERT uses the Transformer encoder architecture—the same one from “Attention Is All You Need,” but without the decoder.
Model sizes
| BERT-Base | BERT-Large | |
|---|---|---|
| Layers (L) | 12 | 24 |
| Hidden size (H) | 768 | 1024 |
| Attention heads (A) | 12 | 16 |
| Parameters | 110M | 340M |
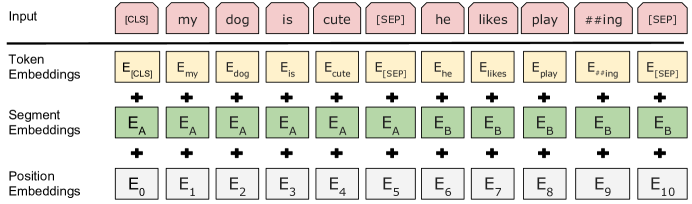
Input representation
Each input token is represented as the sum of three embeddings:
- Token embedding: WordPiece vocabulary of 30,000 tokens
- Segment embedding: Which sentence (A or B) this token belongs to
- Position embedding: Learned (not sinusoidal like the original Transformer)
The computation
Stack of $L$ identical layers, each containing:
- Multi-head self-attention — every position attends to every position
- Feed-forward network — applied independently to each position
Both wrapped with residual connections and layer normalization.
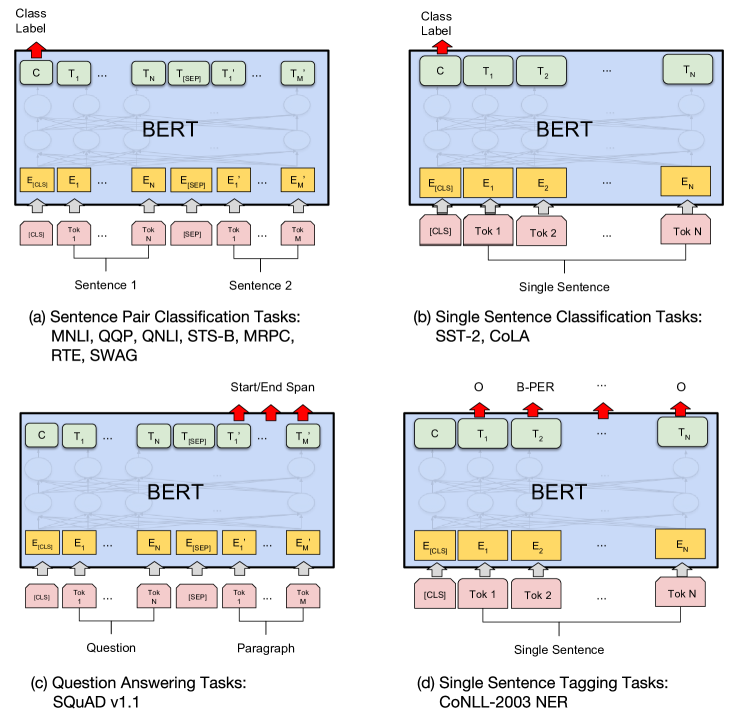
Fine-tuning BERT
The breakthrough of BERT is how simple fine-tuning becomes. For most tasks:
- Take the pre-trained BERT model
- Add a single task-specific layer on top
- Fine-tune all parameters on your labeled data (3-4 epochs)
Hyperparameters for fine-tuning
The authors found most tasks work well with:
- Batch size: 16 or 32
- Learning rate: 5e-5, 3e-5, or 2e-5
- Epochs: 2, 3, or 4
- Dropout: 0.1 (kept from pre-training)
Fine-tuning is fast: minutes to hours on a single GPU for most datasets.
Results
BERT achieved state-of-the-art on 11 NLP benchmarks at the time of publication.
GLUE Benchmark
| Task | Previous SOTA | BERT-Large |
|---|---|---|
| MNLI (accuracy) | 80.6 | 86.7 |
| QQP (F1) | 66.1 | 72.1 |
| QNLI (accuracy) | 87.4 | 92.7 |
| SST-2 (accuracy) | 93.5 | 94.9 |
| CoLA (Matthew's corr) | 35.0 | 60.5 |
| GLUE Average | 72.8 | 80.5 |
SQuAD (Question Answering)
| Human | Previous SOTA | BERT | |
|---|---|---|---|
| SQuAD 1.1 (F1) | 91.2 | 91.7 | 93.2 |
| SQuAD 2.0 (F1) | 89.5 | 78.0 | 83.1 |
BERT exceeded human performance on SQuAD 1.1 and dramatically improved SQuAD 2.0.
Why BERT Works
Several factors contribute to BERT’s success:
1. True bidirectionality
Every position can attend to every other position. Information flows in all directions. This is more powerful than concatenating two unidirectional models.
2. Deep pre-training
12-24 layers of Transformer, pre-trained on billions of words. The model learns rich representations of language structure, syntax, and semantics—all before seeing a single labeled example.
3. Simple fine-tuning
No task-specific architecture needed. The same pre-trained model works for classification, tagging, and question answering. This democratized NLP: you no longer needed to design a new architecture for each task.
Limitations and Trade-offs
Sequence length
BERT is limited to 512 tokens due to memory constraints. For long documents, you need to truncate or use sliding windows.
The [MASK] token
The [MASK] token appears during pre-training but not during fine-tuning. This pre-train/fine-tune mismatch may limit performance. (Later models like XLNet and ELECTRA address this.)
Not a language model
BERT can’t generate text autoregressively like GPT. It’s designed for understanding, not generation. You can’t just “sample from BERT.”
Legacy
BERT sparked an explosion of research. Each successor kept the encoder-plus-pretraining core and pushed on one axis:
| Model | Year | Pushed on | Change |
|---|---|---|---|
| RoBERTa | 2019 | Training recipe | More data, no NSP, longer training |
| ALBERT | 2019 | Efficiency | Parameter sharing across layers |
| DistilBERT | 2019 | Efficiency | Distilled, 40% smaller, ~97% of performance |
| XLNet | 2019 | Objective | Permutation LM, removes the [MASK] mismatch |
| ELECTRA | 2020 | Objective | Replaced-token detection instead of MLM |
| DeBERTa | 2020 | Architecture | Disentangled content and position attention |
And the broader paradigm—pre-train, then fine-tune—became the default for NLP, later extending to GPT-3’s few-shot prompting and today’s large language models.
BERT showed that with enough pre-training, a single architecture could master almost any NLP task. That insight changed the field.
References
-
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL 2019.
-
Peters, M. E., et al. (2018). Deep contextualized word representations (ELMo). NAACL 2018.
-
Radford, A., et al. (2018). Improving Language Understanding by Generative Pre-Training (GPT). OpenAI.
-
Vaswani, A., et al. (2017). Attention Is All You Need. NeurIPS 2017.